The way people interact with mobile applications is changing faster than ever before. For years, mobile apps relied heavily on taps, typed commands, and static interfaces. Today, users expect apps to behave more like intelligent assistants that can see, hear, understand, and respond naturally in real time. This shift is being driven by multimodal AI a transformative technology that combines text, voice, and visual understanding into a single intelligent experience.
From scanning a product image and instantly receiving recommendations to speaking naturally with banking apps or using cameras for healthcare diagnostics, multimodal AI is redefining how businesses build digital experiences. The biggest tech companies in the world are investing heavily in this technology because it fundamentally changes user engagement, accessibility, personalization, and automation.
For businesses, this evolution is not just about innovation. It is about staying competitive in a market where users increasingly prefer intuitive, conversational, and context-aware applications. Companies adopting multimodal AI are improving customer satisfaction, reducing operational friction, and unlocking entirely new interaction models.
We help businesses integrate advanced AI-powered mobile experiences that combine voice, text, and vision into seamless applications designed for modern users. In this detailed guide, we explore how multimodal AI works, the technologies behind it, real-world business applications, UX design strategies, implementation approaches, and the future of intelligent mobile experiences.
What Is Multimodal AI and Why Is It a UX Breakthrough?
Traditional AI systems generally focus on one type of input at a time. A chatbot processes text, a voice assistant handles speech, and an image recognition system analyzes pictures independently. Multimodal AI changes this limitation by allowing systems to process multiple forms of input simultaneously and combine them into a unified understanding.
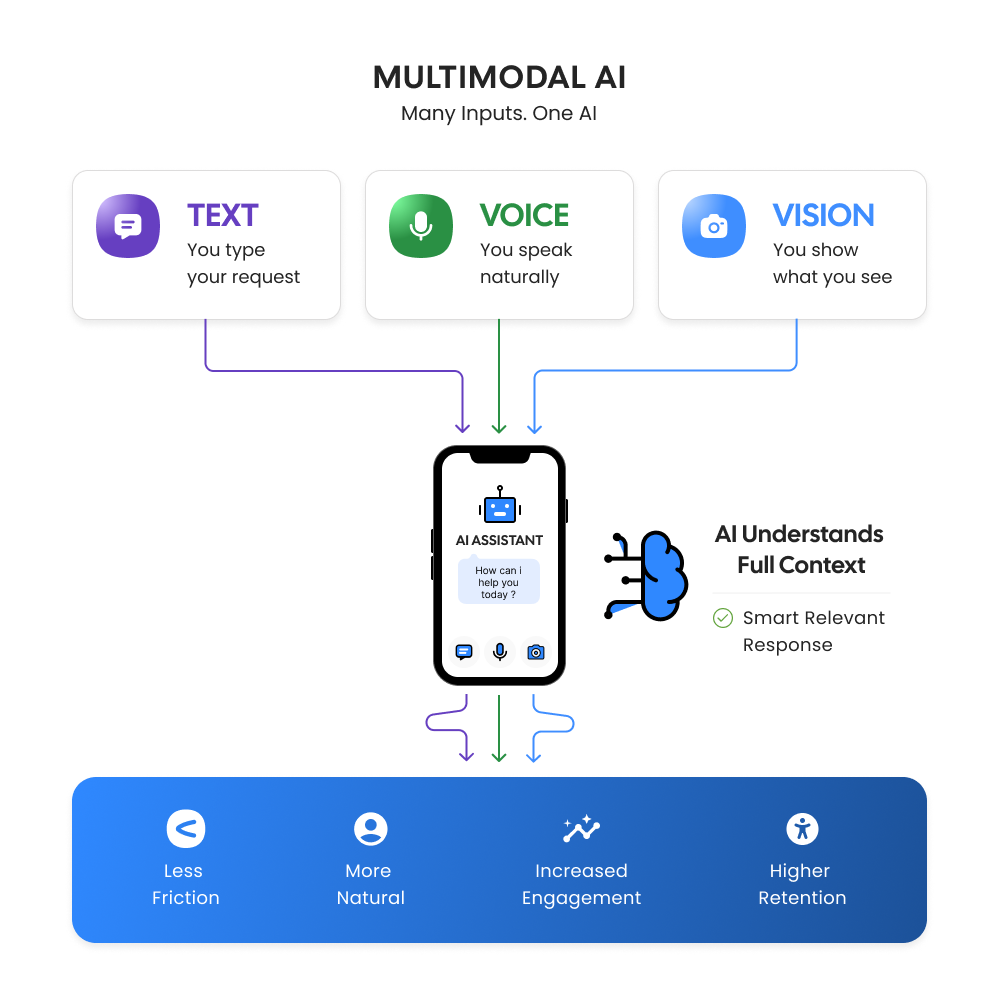
Instead of functioning like disconnected tools, multimodal AI behaves more like human cognition. Humans naturally combine speech, facial expressions, visuals, and contextual understanding when interacting with the world. Multimodal AI attempts to replicate this capability digitally.
Imagine a retail app where a user uploads a picture of shoes, asks a voice question about available sizes, and receives text-based recommendations instantly. The application processes the image, understands the spoken request, and generates contextual responses seamlessly. This creates an interaction model that feels natural and intuitive instead of rigid and mechanical.
The reason multimodal AI is considered a UX breakthrough lies in its ability to reduce friction. Users no longer need to follow predefined workflows or manually navigate complex interfaces. Instead, the app adapts to the user’s preferred communication method.
According to industry reports from leading research firms, AI-powered personalization can improve customer engagement rates by more than 30%, while conversational and voice-driven experiences significantly reduce task completion times. Businesses that leverage these technologies are seeing measurable improvements in customer retention and operational efficiency.
More importantly, multimodal AI supports accessibility in ways traditional interfaces cannot. Users with disabilities can interact through alternate input methods, creating inclusive digital ecosystems that serve wider audiences.
From Single-Input to Multi-Input: How AI Is Learning to Understand Humans
The journey from single-input AI systems to multimodal intelligence reflects the broader evolution of artificial intelligence itself. Earlier AI applications operated in silos. Speech recognition systems understood only audio, while image recognition systems focused solely on computer vision tasks.
Modern AI systems are now capable of combining multiple data streams simultaneously. This evolution became possible due to advancements in transformer architectures, neural networks, edge computing, and large-scale training datasets.
Today’s AI models can correlate voice commands with visual context, understand textual intent, and interpret environmental signals together. This means a mobile application can understand not only what a user says, but also what they are pointing their camera at and the context in which the interaction occurs.
A practical example can be seen in navigation apps. Earlier systems required typed destination inputs. Modern multimodal systems can interpret spoken instructions, recognize landmarks through cameras, and provide augmented reality navigation overlays in real time.
This shift toward contextual intelligence is critical because human communication itself is inherently multimodal. People rarely communicate through text alone. Tone, visuals, gestures, and context all contribute to meaning. Multimodal AI bridges this gap between human behavior and digital systems.
Text + Voice + Vision: The Three Modalities and How They Work Together
Multimodal AI combines three major input modalities to create intelligent mobile experiences:
Text Understanding
Text remains one of the most widely used forms of interaction in digital systems. AI-powered NLP models analyze typed input, interpret intent, identify sentiment, and generate contextual responses.
For instance, in a customer support application, text-based AI can understand complaints, retrieve relevant knowledge base information, and generate personalized responses instantly.
Voice Interaction
Voice interfaces add speed and convenience to user experiences. Instead of typing lengthy commands, users can interact naturally through speech.
Voice AI systems convert spoken language into text using automatic speech recognition (ASR), process intent using NLP, and generate audio responses using text-to-speech (TTS) systems.
This creates conversational experiences that feel far more natural than traditional interfaces.
Computer Vision
Computer vision enables mobile applications to interpret visual data from cameras or uploaded images. AI models can identify objects, analyze documents, recognize faces, detect anomalies, and interpret environments in real time.
Computer vision is particularly transformative in healthcare, retail, logistics, and manufacturing industries.
How These Modalities Work Together
The real power emerges when these three modalities interact simultaneously.
A user could photograph a damaged machine component, describe the issue verbally, and receive AI-generated troubleshooting instructions instantly. The AI system combines visual analysis with spoken context to produce accurate and context-aware results.
This fusion of modalities significantly enhances user experience because it mirrors real-world human interaction patterns.
The Technology Stack Behind Multimodal AI in Mobile Apps
Building multimodal AI applications requires sophisticated technology stacks that integrate several AI disciplines into unified systems.
These systems rely on cloud infrastructure, edge computing, neural accelerators, APIs, and mobile AI frameworks to deliver real-time performance.
Below is a comparison of core multimodal AI technologies commonly used in modern mobile apps:
|
Technology Area
|
Popular Tools & Platforms
|
Primary Use Case
|
|
Natural Language Processing
|
GPT-4o, Gemini, Claude
|
Conversational AI and text understanding
|
|
Speech Recognition
|
Whisper, Google Speech-to-Text
|
Voice command processing
|
|
Text-to-Speech
|
ElevenLabs, Amazon Polly
|
AI-generated voice responses
|
|
Computer Vision
|
MediaPipe, OpenCV, TensorFlow Lite
|
Object and image recognition
|
|
Mobile AI Optimization
|
Apple Neural Engine, Google Tensor
|
On-device inference
|
|
AR & Spatial Computing
|
Apple Vision Pro SDK, ARCore
|
Immersive multimodal experiences
|
These technologies work together to create seamless user experiences across devices and operating systems.
NLP for Text: GPT-4o, Gemini, and On-Device LLMs
Natural Language Processing is the foundation of intelligent conversational interfaces. Modern NLP systems are far more advanced than traditional chatbots because they understand context, intent, and conversational flow.
Models like OpenAI GPT-4o and Google Gemini can process complex queries, summarize information, generate responses, and even reason across multiple forms of input.
One major trend shaping mobile AI is the rise of on-device LLMs. Instead of sending every request to cloud servers, compact AI models can now run directly on smartphones.
This approach offers several advantages:
- Reduced latency
- Improved privacy
- Lower cloud costs
- Better offline functionality
- Faster response times
For example, flagship smartphones powered by Apple Neural Engine and Google Tensor chips are increasingly capable of running AI models locally, making intelligent experiences faster and more secure.
ASR for Voice: Whisper, Google Speech-to-Text, and ElevenLabs TTS
Voice AI systems rely heavily on ASR and TTS technologies.
Automatic Speech Recognition converts spoken words into machine-readable text. Advanced systems such as Whisper can handle accents, background noise, multilingual conversations, and real-time transcription with impressive accuracy.
Text-to-Speech engines then convert AI-generated responses back into human-like speech.
Modern TTS systems are becoming emotionally expressive, context-aware, and highly natural sounding. This improves engagement dramatically in virtual assistants, customer service apps, and accessibility-focused applications.
A real-world example can be seen in customer support automation. Instead of navigating frustrating IVR systems, users can now speak naturally with AI-powered assistants that understand intent and provide contextual support instantly.
According to several enterprise studies, voice-enabled support systems can reduce average handling times by up to 35%.
Computer Vision: Real-Time Object Recognition, Apple Vision Pro, and MediaPipe
Computer vision enables mobile devices to understand the physical world visually.
Modern mobile apps can recognize products, scan documents, identify defects, analyze medical imagery, and track gestures in real time.
Technologies such as MediaPipe and TensorFlow Lite allow developers to build lightweight computer vision models optimized for smartphones.
Meanwhile, spatial computing platforms like Apple Vision Pro are expanding multimodal experiences into immersive environments where voice, gesture, eye tracking, and visual overlays combine into a unified interface.
Real-time object recognition is particularly valuable in retail and logistics. Warehouse workers can point cameras at inventory items while receiving AI-generated instructions through voice feedback simultaneously.
This reduces errors, improves efficiency, and speeds up operations significantly.
On-Device vs. Cloud Inference: Apple Neural Engine and Google Tensor Chips
One of the biggest architectural decisions in multimodal AI development involves choosing between on-device inference and cloud-based processing.
On-device AI processes data directly on smartphones using specialized hardware accelerators. Cloud inference sends data to remote servers for processing.
Both approaches have strengths and limitations.
|
Factor
|
On-Device AI
|
Cloud AI
|
|
Speed
|
Faster local responses
|
Dependent on internet speed
|
|
Privacy
|
Better privacy protection
|
Requires data transmission
|
|
Battery Usage
|
Can increase local power consumption
|
Lower local device load
|
|
Scalability
|
Limited by device hardware
|
Virtually unlimited processing
|
|
Offline Functionality
|
Works without internet
|
Internet dependent
|
|
Model Complexity
|
Smaller optimized models
|
Large advanced AI models
|
Most enterprise-grade applications today use hybrid architectures where sensitive or latency-critical tasks run locally, while larger computational tasks leverage cloud infrastructure.
Real-World Use Cases Across Industries
Multimodal AI is already transforming industries worldwide by enabling smarter interactions, automation, and contextual decision-making.
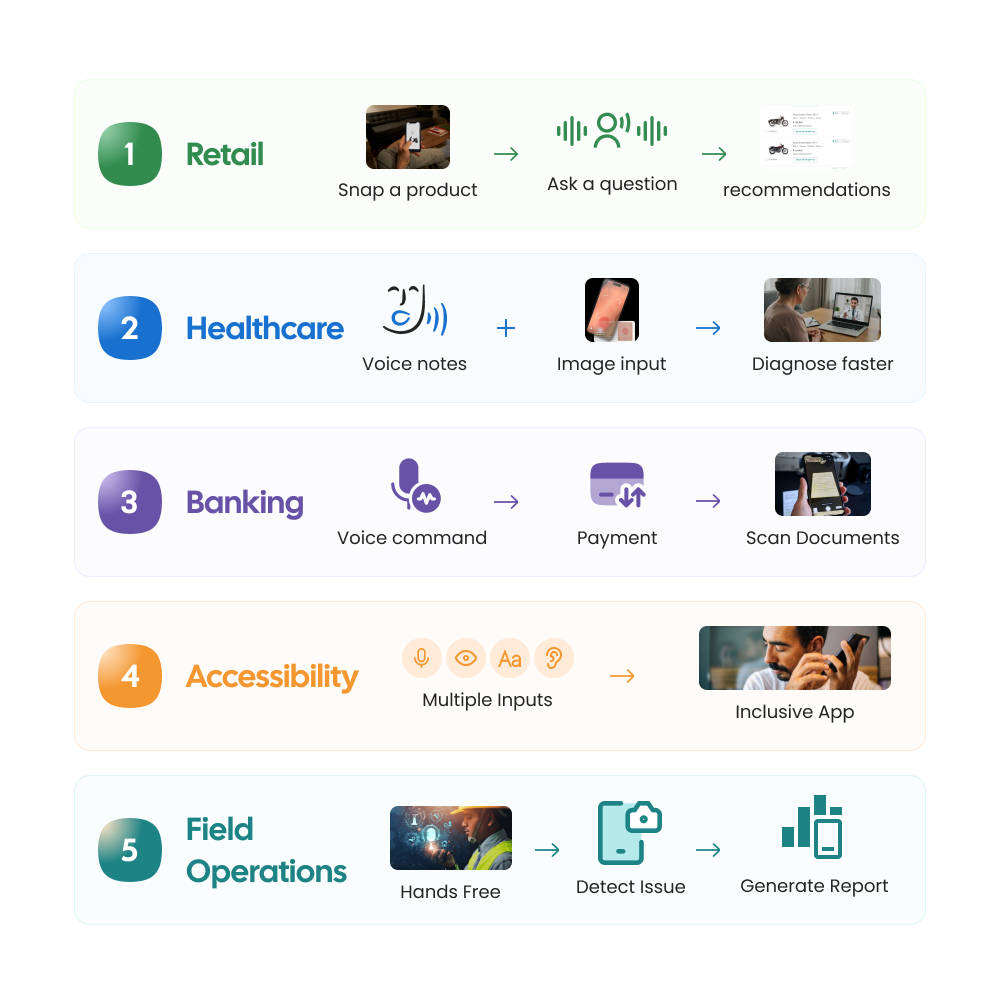
Retail: Photograph a Product, Ask a Question, Get an Instant Answer
Retail applications are rapidly adopting multimodal AI to improve shopping experiences.
Imagine a customer photographing a chair they like in a cafe. The app identifies the product visually, searches similar inventory, answers spoken questions about pricing or dimensions, and recommends matching furniture instantly.
This creates highly personalized shopping journeys that reduce friction and increase conversion rates.
Several global retailers are already integrating visual search and conversational AI into mobile commerce platforms to improve engagement and reduce cart abandonment.
Healthcare: Voice-Driven Clinical Documentation and Symptom Input via Image
Healthcare professionals spend enormous amounts of time on documentation and administrative work.
Multimodal AI helps reduce this burden significantly.
Doctors can verbally describe patient conditions while AI systems generate structured medical notes automatically. Patients can upload images of symptoms for preliminary analysis while simultaneously describing discomfort through voice input.
This accelerates diagnosis workflows and improves operational efficiency.
In rural or underserved areas, AI-powered mobile healthcare applications can assist with early-stage triage where specialist access is limited.
Banking: Voice Commands for Payments Combined with Document Scanning
Banking apps are becoming increasingly conversational and intelligent.
Users can now authenticate transactions through voice, scan documents using cameras, and receive contextual financial insights through conversational AI.
For example, a customer might say:
“Transfer 10,000 USD to my savings account and scan this cheque.”
The AI system combines voice intent recognition with document analysis to execute the task seamlessly.
This reduces manual steps and creates faster, more intuitive banking experiences.
Accessibility: Enabling Users with Disabilities Through Alternate Input Modes
One of the most impactful applications of multimodal AI is accessibility.
Users with mobility limitations may prefer voice interactions, while visually impaired users benefit from audio descriptions and conversational interfaces.
Similarly, users with hearing impairments may rely more heavily on visual and text-based interactions.
By supporting multiple input methods simultaneously, multimodal applications create inclusive digital experiences that adapt to diverse user needs.
This is not just socially important it also expands addressable market reach for businesses significantly.
Field Operations: Hands-Free Android Apps with Voice + Camera for Inspection
Field workers often operate in environments where typing on mobile devices is impractical or unsafe.
Multimodal AI enables hands-free workflows through voice commands and camera-based analysis.
An inspector can verbally record notes while scanning equipment visually through the device camera. AI systems can detect defects, generate inspection reports, and provide contextual recommendations instantly.
This dramatically improves productivity and reduces human error in industries such as logistics, utilities, construction, and manufacturing.
Designing Multimodal UX: Principles and Best Practices
Designing multimodal experiences requires a different mindset compared to traditional UI/UX design.
The focus shifts from screen-centric interfaces to context-aware interaction systems.
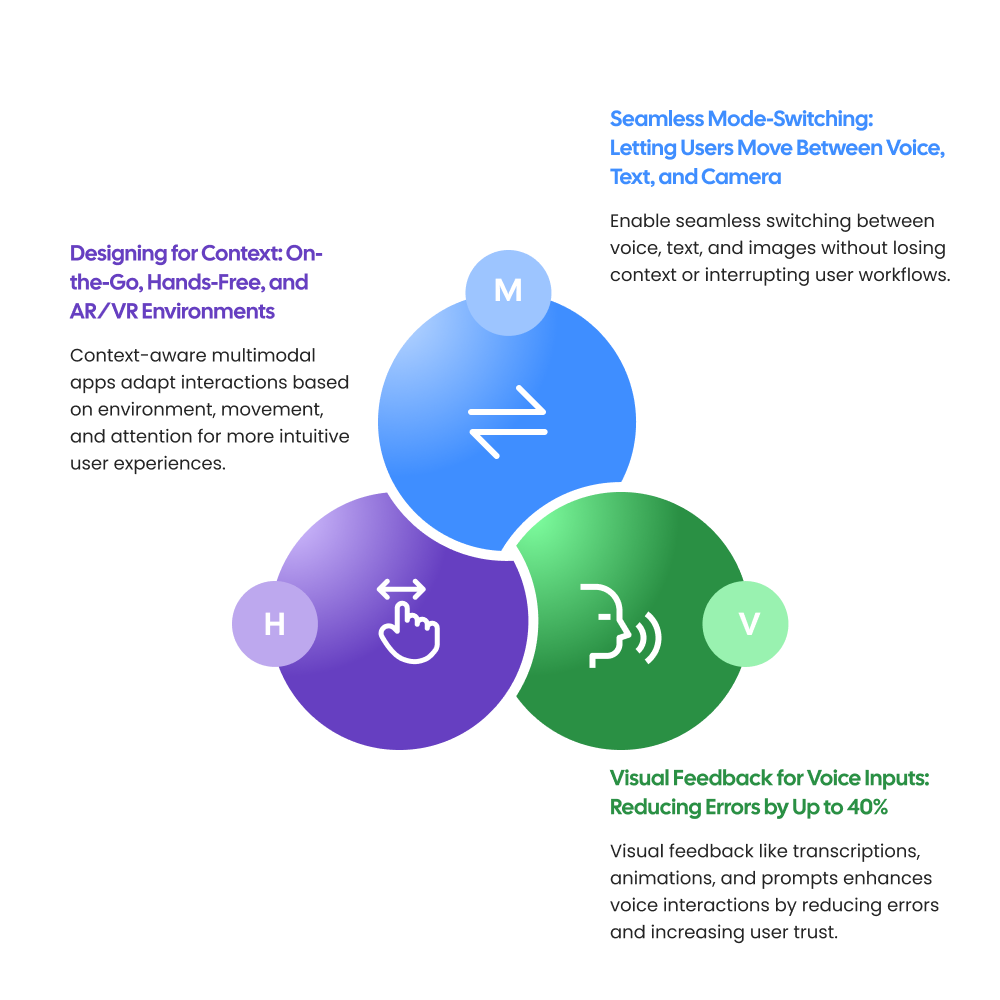
Seamless Mode-Switching: Letting Users Move Between Voice, Text, and Camera
Users should be able to switch naturally between modalities without friction.
For example, a user may begin a conversation using voice but continue through text in a noisy environment. Similarly, they may upload an image mid-conversation for additional context.
Applications should support these transitions seamlessly without resetting workflows or losing context.
The best multimodal experiences feel fluid and adaptive rather than segmented.
Visual Feedback for Voice Inputs: Reducing Errors by Up to 40%
Voice interfaces become significantly more effective when paired with visual confirmation systems.
For example, when users speak commands, displaying recognized text visually helps reduce misunderstandings and improves trust.
Research across conversational UX studies indicates that visual feedback mechanisms can substantially reduce interaction errors and improve user confidence.
Simple indicators such as transcription previews, waveform animations, and contextual prompts improve usability dramatically.
Designing for Context: On-the-Go, Hands-Free, and AR/VR Environments
Context matters enormously in multimodal design.
A user driving a car requires different interaction patterns compared to a user sitting at a desk. Similarly, warehouse workers wearing AR devices need optimized voice and gesture interactions.
Successful multimodal apps adapt dynamically based on user environment, movement, and available attention span.
Context-aware UX design is becoming one of the defining characteristics of next-generation mobile applications.
How to Integrate Multimodal AI into Your Existing Mobile App
Many businesses assume multimodal AI requires rebuilding applications from scratch. In reality, most companies can integrate these capabilities incrementally.
A phased implementation strategy minimizes risk while delivering measurable value quickly.
Starting with One Modality and Expanding: A Practical Roadmap
Businesses should begin with the modality that solves their most immediate user pain point.
For instance:
- E-commerce apps may start with visual search.
- Banking apps may prioritize voice assistants.
- Healthcare apps may begin with AI-powered documentation.
Once the initial capability proves successful, additional modalities can be integrated progressively.
This phased approach reduces complexity and allows teams to validate ROI at each stage.
APIs vs. On-Device Models: Choosing the Right Approach for Your Use Case
Choosing between APIs and local AI models depends heavily on business priorities.
Cloud APIs provide rapid implementation and access to highly advanced models. However, they may introduce privacy concerns, latency issues, and recurring operational costs.
On-device AI offers stronger privacy protections and offline functionality but requires optimization expertise and hardware-aware development.
Most enterprise applications use hybrid architectures balancing both approaches strategically.
We help businesses evaluate the right AI deployment strategy based on scalability goals, compliance requirements, performance expectations, and operational costs.
Challenges and Limitations of Multimodal AI in Mobile Apps
Despite its enormous potential, multimodal AI also introduces technical and operational challenges.
Latency, Battery Consumption, and Model Size on Mobile
AI models are computationally intensive.
Running multimodal systems continuously on smartphones can impact battery life, device temperature, and application performance.
Developers must optimize models carefully using compression, quantization, and edge AI frameworks.
Balancing responsiveness with energy efficiency remains a major engineering challenge.
Privacy Concerns: Who Processes the Voice and Vision Data?
Privacy remains one of the most important concerns in multimodal AI adoption.
Voice recordings, facial imagery, and contextual behavioral data are highly sensitive.
Businesses must implement:
- Strong encryption
- Transparent consent policies
- Local data processing where possible
- Secure cloud storage practices
- Compliance with global privacy regulations
Consumers are increasingly aware of data privacy risks, making trust a critical competitive differentiator.
The Future: Emotion-Aware and Context-Aware Multimodal Apps

The future of multimodal AI extends far beyond simple voice assistants or image recognition.
Next-generation systems are becoming emotionally aware and contextually intelligent.
AI models are beginning to detect emotional tone, stress levels, environmental conditions, and behavioral patterns.
Future applications may adapt dynamically based on user mood, physical activity, or environmental context.
For example:
- Fitness apps may detect fatigue through voice patterns.
- Customer service systems may escalate frustrated users automatically.
- Healthcare apps may identify emotional distress indicators during conversations.
- Educational apps may personalize learning styles based on engagement patterns.
This evolution will fundamentally transform human-computer interaction over the next decade.
According to multiple market forecasts, the global multimodal AI market is expected to grow exponentially as businesses increasingly prioritize intelligent, human-centric digital experiences.
Conclusion
Multimodal AI is rapidly becoming one of the most important innovations in mobile application development. By combining text, voice, and vision into unified intelligent systems, businesses can create faster, smarter, and more human-centered user experiences.
From healthcare and banking to retail and logistics, multimodal AI is unlocking new operational efficiencies, improving accessibility, and redefining digital engagement standards.
The companies that adopt these technologies early will gain significant competitive advantages in customer experience, automation, and personalization.
However, successful implementation requires more than simply integrating AI APIs. Businesses must carefully design user experiences, optimize performance, ensure privacy compliance, and align technology choices with long-term business goals.
At TechQware Technologies, we specialize in building AI-powered mobile applications that combine advanced multimodal capabilities with scalable, secure, and user-centric design principles.
If your organization is planning to integrate conversational AI, voice interfaces, computer vision, or intelligent automation into mobile applications, our team can help you build future-ready digital products tailored to your business objectives.
Connect with Us to develop next-generation AI-powered applications that combine text, voice, and vision for seamless user engagement, operational efficiency, and scalable business growth.
Whether you are modernizing an existing app or building an AI-first digital platform from scratch, our experts can help you transform innovative ideas into intelligent user experiences.
FAQs
What is multimodal AI and how is it different from regular AI?
Multimodal AI refers to artificial intelligence systems capable of processing multiple types of inputs simultaneously, such as text, voice, images, and video. Traditional AI systems usually specialize in only one modality at a time. Multimodal AI combines these inputs into a unified contextual understanding, making interactions significantly more natural and intelligent.
Can AI understand both voice and images at the same time?
Yes, modern multimodal AI systems can process voice commands and visual data simultaneously. For example, a user can upload an image of a product while asking a spoken question about it. The AI system analyzes both inputs together to generate more accurate and context-aware responses.
What is on-device AI and why is it better for privacy?
On-device AI refers to AI processing that occurs directly on smartphones or local devices instead of cloud servers. This approach improves privacy because sensitive data such as voice recordings or images do not need to leave the user’s device. It also reduces latency and enables offline functionality.
How does Google Gemini use multimodal AI in Android apps?
Google Gemini supports multimodal interactions by processing text, voice, images, and contextual data together. In Android applications, it enables advanced conversational experiences, image understanding, smart assistance, and AI-powered recommendations integrated across the mobile ecosystem.
What industries benefit most from multimodal AI in mobile apps?
Industries benefiting significantly from multimodal AI include healthcare, retail, banking, logistics, education, manufacturing, customer support, and accessibility-focused services. These industries use multimodal systems to automate workflows, improve user engagement, and deliver more personalized experiences.
How do I add voice and vision AI to my existing mobile app?
Businesses can integrate multimodal AI gradually by starting with APIs or SDKs for speech recognition, computer vision, or conversational AI. A phased roadmap allows organizations to validate user adoption and ROI before expanding into full multimodal experiences. Partnering with experienced AI development companies like TechQware Technologies can accelerate implementation while ensuring scalability and security.

 TechQware
TechQware