The digital landscape of 2026 is defined by a singular, explosive trend: the integration of artificial intelligence into every facet of the mobile experience. As we witness the exponential growth of AI-powered applications, the bar for user expectations has been raised to unprecedented heights. Users no longer want generic, canned responses from a chatbot; they demand precise, context-aware, and real-time information delivered instantly within their favorite apps.
However, developers and businesses have quickly run into the inherent limitations of standalone Large Language Models (LLMs). While models like GPT-4 or Gemini are incredibly sophisticated, they are "frozen in time" based on their last training cutoff. They lack access to your specific company's private documents, today’s fluctuating stock prices, or the live inventory of a retail app. This gap between general reasoning and specific, real-time knowledge is where many AI projects fail.
For businesses to stay competitive, real-time knowledge integration is no longer a "nice-to-have" feature it is a survival requirement. This is where Retrieval-Augmented Generation (RAG) emerges as the definitive solution. RAG bridges the gap between the creative reasoning of Large Language Models in Mobile App Development and the factual accuracy of private, external data sources. In this guide, we will explore how RAG is revolutionizing the mobile industry by turning hallucination-prone AI into reliable, enterprise-grade assistants.
What Is Retrieval-Augmented Generation (RAG)?
Simple Definition of RAG
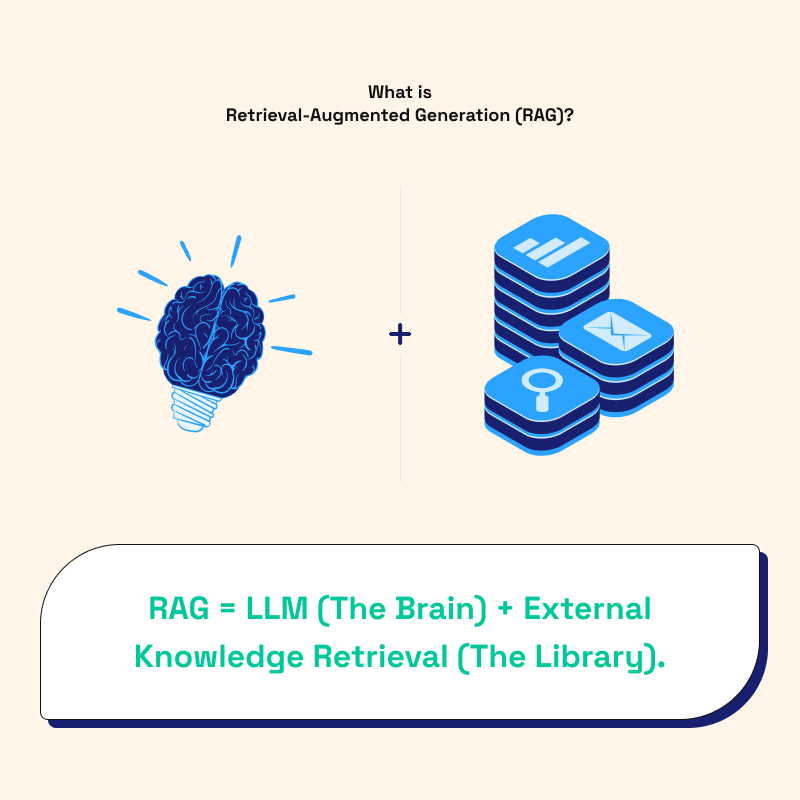
At its core, Retrieval-Augmented Generation (RAG) is an architectural framework that optimizes the output of an LLM by pointing it toward a specific, trusted body of knowledge before it generates a response. To put it simply:
RAG = LLM (The Brain) + External Knowledge Retrieval (The Library)
Imagine an open-book exam. A standard LLM is like a student trying to answer questions based solely on their memory from a class they took a year ago. A RAG-enabled system is like that same student, but with full access to a comprehensive, up-to-date textbook during the exam. The student (LLM) uses their intelligence to understand the question and the textbook (Retrieval) to find the exact facts required for the answer.
Why RAG Matters for Modern AI Applications
Traditional generative models suffer from three major pitfalls that make them risky for professional mobile applications. First is outdated knowledge; if a model was trained in 2025, it cannot tell a user about a product launched in 2026. Second is the infamous problem of hallucinations, where the AI confidently invents facts when it doesn't know the answer. Third is limited enterprise data access; generic models have never seen your internal HR policies, your proprietary medical research, or your customer’s specific purchase history.
Understanding the shift from AI vs Generative AI is crucial here. While Generative AI creates content, RAG ensures that content is grounded in reality. By providing a "ground truth" through retrieval, RAG drastically reduces the chances of an app giving a user incorrect or dangerous information, making it the backbone of trust in modern software.
Research & Industry Insights on Retrieval-Augmented Generation
As we progress through 2026, research insights from leading AI organizations like OpenAI, Anthropic, and DeepMind indicate that RAG has become the preferred method for enterprise AI over traditional fine-tuning. While fine-tuning adjusts the model's behavior, RAG adjusts its knowledge base, which is far more cost-effective and easier to update.
Adoption trends in enterprise AI show that nearly 80% of businesses deploying AI assistants are now utilizing some form of RAG architecture. The primary driver is accuracy. Industry statistics demonstrate that RAG can reduce LLM hallucinations by as much as 75% to 90% depending on the quality of the retrieval source. This accuracy improvement is what allows sectors like legal and healthcare to finally embrace AI.
Furthermore, the role of vector databases has moved from a niche developer tool to a cornerstone of modern AI architecture. Companies are realizing that their data is their greatest asset, and RAG provides a secure way to use that data without leaking it into the public training sets of foundational models. This ensures data sovereignty while maintaining cutting-edge performance.
How Retrieval-Augmented Generation Works
The RAG workflow is a sophisticated four-step loop that happens in milliseconds behind the mobile app interface.
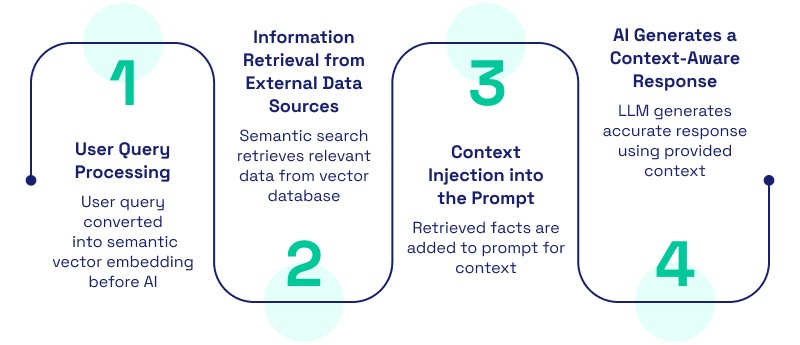
Step 1 – User Query Processing
The process begins when a user enters a prompt into the mobile app for example, "What is the return policy for the shoes I bought yesterday?" The system doesn't just send this to the AI. First, it processes the query, often converting it into a numerical format called a "vector embedding" that captures the semantic meaning of the words.
Step 2 – Information Retrieval from External Data Sources
Armed with the vector embedding, the system searches a Vector Database containing the company's specific data (return policies, purchase history, etc.). Unlike a keyword search that looks for exact matches, this is a "semantic search" that looks for the meaning behind the query. It identifies the most relevant snippets of information from the "external library."
Step 3 – Context Injection into the Prompt
Now comes the "Augmented" part of RAG. The system takes the original user query and "stuffs" it with the retrieved facts. The prompt sent to the LLM looks something like this: "You are a helpful assistant. Using the following verified facts: [Fact A: User bought shoes on April 1st. Fact B: Return policy is 30 days], please answer the user's question: [How do I return my shoes?]"
Step 4 – AI Generates a Context-Aware Response
The LLM receives the enriched prompt. Instead of guessing, it simply rephrases the provided facts into a natural, conversational response. The mobile app then displays: "Since you bought your shoes on April 1st, you have until May 1st to return them. Would you like me to start the return process?"
Core Components of a RAG System
Large Language Models (LLMs)
The LLM acts as the reasoning engine. Its job is to understand language, follow instructions, and format the final output. In the context of Large Language Models in Mobile App Development, developers must choose a model that balances speed (latency) with reasoning capability, as mobile users expect near-instant responses.
Vector Databases and Embeddings
A vector database is the storage facility for your data. Before data is stored, it is passed through an "embedding model" that turns text into long strings of numbers (vectors). These numbers represent the "coordinates" of an idea in a multi-dimensional space. Semantic search works by finding the data points that are mathematically closest to the user's query.
Retrieval Layer
The retrieval layer is the "middleman" or orchestrator. It manages the communication between the user's device, the vector database, and the LLM. It is responsible for ranking the retrieved data to ensure only the most relevant snippets are passed to the AI, preventing "context window" overflow.
Knowledge Sources
RAG can pull from virtually any digital source:
- Enterprise Documents: PDFs, Word docs, or internal Wikis.
- Product Catalogs: Real-time inventory and pricing.
- Knowledge Bases: FAQ sections and help articles.
- APIs: Live weather, stock prices, or shipping trackers.
- Databases: Structured customer data and transaction logs.
Benefits of Retrieval-Augmented Generation for AI Applications

The benefits of RAG are transformative for both the developer and the end-user. First and foremost is improved response accuracy. By grounding the AI in facts, the "creative writing" aspect of LLMs is reined in, ensuring the information provided is 100% factual.
Furthermore, RAG allows for real-time knowledge access. Unlike a model that requires months of retraining to learn new facts, a RAG system learns instantly. If you upload a new price list to your database, the AI can start quoting those prices one second later. This leads to reduced hallucinations, as the AI is instructed to say "I don't know" if the information isn't found in the retrieved snippets.
From a business perspective, enterprise knowledge integration and better personalization are the biggest wins. An app can tailor its advice based on the user's unique profile, making the mobile experience feel truly bespoke. This is a core part of How AI and Generative AI Are Transforming Mobile Apps in the current market.
RAG vs Traditional Generative AI Models
To understand the superiority of RAG for enterprise use, consider this comparison table:
|
Feature
|
Traditional LLM
|
RAG
|
|
Knowledge Updates
|
Static (Requires retraining/fine-tuning)
|
Real-time (Update the database)
|
|
Accuracy
|
Medium (Prone to hallucinations)
|
High (Grounded in facts)
|
|
Enterprise Data Integration
|
Limited (Public data only)
|
Strong (Connects to private data)
|
|
Personalization
|
Limited (General responses)
|
Context-aware (User-specific data)
|
|
Cost
|
High (Retraining is expensive)
|
Low (Database storage is cheap)
|
How Retrieval-Augmented Generation Is Used in Mobile Apps
This is the most critical area for businesses looking to enhance their mobile offerings.
AI Customer Support Assistants in Mobile Apps
Modern support bots are no longer frustrating. By using RAG, these apps retrieve information from help center documentation, FAQs, and real-time product information. A user can ask, "Why is my subscription pending?" and the app can look up the user's billing status and the latest server logs to provide an exact answer.
Intelligent In-App Search
Traditional search is based on keywords. If you search for "cold weather clothes," a traditional app might show nothing if that exact phrase isn't in a product title. A RAG-powered intelligent in-app search understands that you mean jackets, beanies, and scarves, retrieving them via semantic similarity.
Personalized Product Recommendations
RAG can move beyond "people who bought this also bought that." By retrieving purchase history, browsing behavior, and complex product catalogs, the AI can explain why it is recommending a product: "I’m suggesting this tent because you viewed 4-person camping gear last week and it’s currently on sale."
Enterprise Knowledge Assistants
Mobile apps for employees such as employee training apps, healthcare knowledge systems, and financial advisory apps benefit immensely from RAG. A doctor can use a mobile app to retrieve the latest clinical guidelines for a rare condition, or a financial advisor can instantly pull the latest market insights while on a client call.
Real-World Use Cases of RAG in Mobile Applications
Healthcare Apps
In the medical field, accuracy is a matter of life and death. RAG-powered apps allow practitioners to retrieve the most recent medical guidelines and research papers. Instead of relying on a model's general training, the app can cite specific peer-reviewed studies to assist in diagnosis.
E-Commerce Apps
E-commerce giants are using RAG for smart product discovery. By allowing users to describe what they need in natural language ("I need a dress for a summer wedding in Tuscany"), the RAG system retrieves items that match the "vibe" and "context" rather than just the tags.
Financial Apps
Banking & investment apps use RAG to provide real-time financial insights. When a user asks about their spending habits, the app retrieves their transaction history and compares it against current inflation data or market trends to provide personalized budgeting advice.
Travel Apps
Travelers deal with constantly changing variables. RAG enables apps to retrieve real-time travel information, such as flight delays, gate changes, and weather alerts, integrating this data into a conversational interface that helps users rebook on the fly.
Developer Insights: Building RAG-Powered Mobile Applications
Building a RAG system is a journey into modern data engineering. Developers frequently combine vector databases with LLMs because it offers the best balance of speed and reliability. However, one of the primary challenges is optimizing retrieval latency. Mobile users are notoriously impatient; if the "retrieval" takes 5 seconds, the user experience is ruined. This requires highly optimized indexing and efficient "chunking" of data.
Handling large knowledge bases is another hurdle. If you provide the AI with too much irrelevant information (noise), the quality of the response drops a phenomenon known as "lost in the middle." Best practices involve implementing a re-ranking step, where a smaller, faster model determines which of the 10 retrieved snippets are truly the top 3 most relevant before sending them to the main LLM. Integrating RAG into mobile app backends also requires a focus on asynchronous processing to keep the UI smooth while the "thinking" happens.
How to Implement RAG in Mobile App Development
If you are ready to build, here is the technical roadmap:
Step 1: Choose the Right Large Language Model
Select a model based on your needs. For mobile, smaller models like Llama-3 (8B) or Gemini Nano are gaining popularity for their speed, while larger models like GPT-4o are used for complex reasoning tasks.
Step 2: Create Embeddings for Your Data
Pass your documents through an embedding model (like OpenAI’s text-embedding-3-small or HuggingFace models) to convert your text into vectors.
Step 3: Store Data in a Vector Database
Choose a database like Pinecone, Weaviate, or Milvus. These databases are specifically designed to handle "nearest neighbor" searches at high speeds.
Step 4: Build the Retrieval Layer
Develop the logic that takes user input, converts it to a vector, queries the database, and formats the "augmented" prompt. Tools like LangChain or LlamaIndex are industry standards for this.
Step 5: Integrate the RAG System with the Mobile App Backend
Connect your mobile frontend to your RAG-enabled backend via a secure API. Ensure you have proper error handling for when the retrieval service is down or no relevant data is found.
Challenges of Implementing RAG in Mobile Apps
While powerful, RAG is not without its difficulties. Infrastructure complexity is a significant hurdle; you are now managing a database, an embedding model, and an LLM, all while ensuring they talk to each other seamlessly. Latency issues remain at the forefront, especially on mobile networks that may be slower than broadband.
Managing large vector databases can also become expensive as your data grows. Furthermore, data privacy and security concerns are paramount. When building a RAG system, you must ensure that a user can only retrieve information they have the rights to see. You wouldn't want a general employee's query to accidentally retrieve the CEO's private payroll data just because it was "semantically relevant."
Future of Retrieval-Augmented Generation in AI Applications
Looking toward the end of 2026 and beyond, we are moving toward multimodal RAG systems. This means the AI won't just retrieve text; it will retrieve images, videos, and audio. Imagine asking a repair app "How do I fix this?" and it retrieves the exact 10-second clip from a 2-hour manual that shows your specific engine part.
We are also seeing the rise of AI agents using RAG. Instead of just answering a question, these agents will use the retrieved information to act booking a flight, moving money, or updating a Jira ticket. Additionally, real-time knowledge graph integrations will allow RAG to understand the relationships between people, places, and things, leading to even more sophisticated reasoning.
Why Businesses Are Adopting RAG for AI-Powered Applications
The business case for RAG is undeniable. It provides improved AI reliability, which is the single biggest barrier to AI adoption in regulated industries. It allows for enterprise knowledge integration, turning every mobile app into a portal to the company's collective intelligence. Finally, it offers a scalable AI architecture; as your company grows, you simply add more data to the library without having to rebuild the "brain."
At TechQware Technologies, a trusted mobile app development company, we specialize in building AI-powered mobile apps with advanced RAG capabilities tailored to your business needs.
Ready to build smarter, more reliable AI apps? Let’s turn your data into a competitive advantage connect with our experts today and start your RAG-powered app journey.
FAQs
What is Retrieval-Augmented Generation in AI?
RAG is an AI framework that retrieves relevant facts from an external database to provide more accurate and context-aware responses through a Large Language Model.
How does RAG improve AI accuracy?
By providing the AI with specific, verified facts to use in its response, RAG prevents the model from having to rely on its own training data, which might be outdated or incomplete, thereby reducing hallucinations.
How is RAG different from fine-tuning?
Fine-tuning is like "teaching" a model a new skill by changing its internal weights. RAG is like giving a model a "reference book." RAG is generally faster, cheaper, and easier to update for factual information.
Why is RAG important for mobile apps?
Mobile users need specific, real-time answers (like order status or local availability) that general AI models cannot provide without access to external, live data sources.